

“You see, there is a branch of human knowledge known as symbolic logic, which can be used to prune away all sorts of clogging deadwood that clutters up human language." - Salvor Hardin in Isaac Asimov’s Foundation
Large Language Models (LLMs) like GPT-4 Turbo, Claude 2.1, Gemini, and Llama 2-70B are remarkable. But they have serious flaws.
They spew falsehoods and hallucinations, and more fundamentally, they lack a grounded model of the world.
In a phenomenal New York Times Op-Ed, Noam Chomsky wrote that LLMs are “incapable of distinguishing the possible from the impossible”, and as a result, “they either overgenerate (producing both truths and falsehoods, endorsing ethical and unethical decisions alike) or undergenerate (exhibiting noncommitment to any decisions and indifference to consequences).”
The problem: LLMs lack a model of reality
Instead of reasoning through problems, LLMs are neural networks that predict the next word in a sentence. It’s tempting to believe the former, though, after seeing this chart from OpenAI about how GPT4 nailed so many exams:
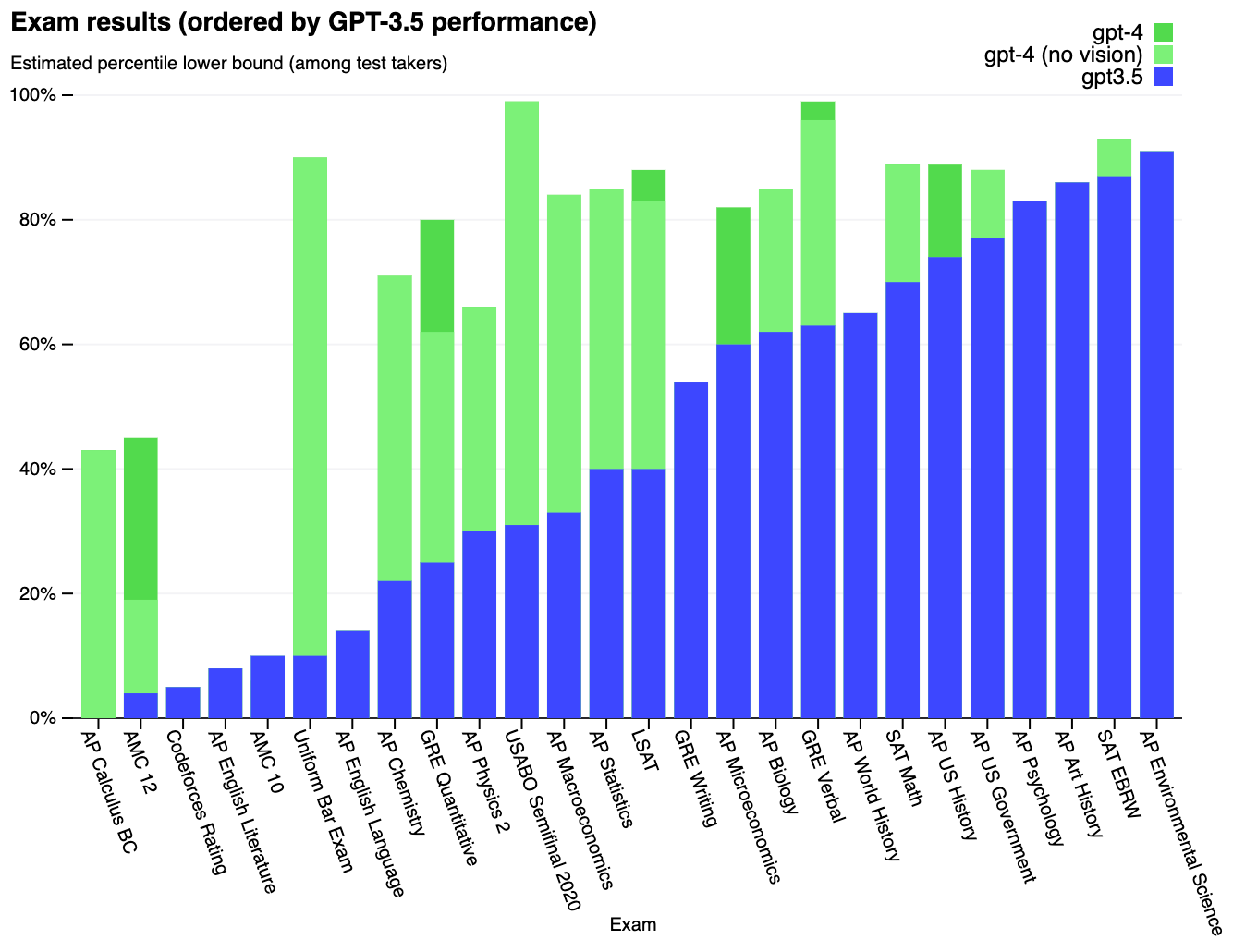
But as Arvind Narayanan and Sayash Kapoor point out, these models may just be regurgitating memorized snippets from their training data (the entire internet) and are being evaluated on the wrong benchmarks. The models’ answer process is rooted in prediction and pattern-matching rather than genuine understanding.
Even if these LLMs aren’t reasoning, as Andrej Karpathy says in this great talk, “in this next word prediction, you’re learning a ton about the world, and all this knowledge is being compressed into the [model’s] weights”.
For example, in this Wikipedia article about Steve Jobs, if we focus on the underlined parts, we can learn that Jobs dropped out of Reed College, co-founded Apple with Steve Wozniak, and pioneered the personal computer revolution with the Apple II.

Let’s put this to the test with GPT 4:

Not too shabby!
In his article “ChatGPT Is a Blurry JPEG of the Web” (love the analogy), Ted Chiang explains,
“Large language models identify statistical regularities in text. Any analysis of the text of the Web will reveal that phrases like “supply is low” often appear in close proximity to phrases like “prices rise.” A chatbot that incorporates this correlation might, when asked a question about the effect of supply shortages, respond with an answer about prices increasing. If a large language model has compiled a vast number of correlations between economic terms—so many that it can offer plausible responses to a wide variety of questions—should we say that it actually understands economic theory?”
I believe that these statistical regularities in text may correlate with genuine knowledge but do not imply a deeper understanding of the world.
Let’s review some basic linguistics to double-click into what LLMs are actually “learning” about the world here.
Linguistics 1.01: syntactic vs semantic features
Two fundamental lenses to analyze language are syntax and semantics. Syntax looks at the structure of language– the order of words and grammar in a sentence. Semantics considers the meaning of those words. Without ever explicitly being told these rules, by looking at billions of human sentences, LLMs have learned to approximate them, albeit crudely at times.
Take syntactic features. LLMs have essentially “learned” common grammatical patterns (i.e. subject-verb agreement, not putting 2 nouns next to each other, forming valid parse trees, etc.) and are fairly good at following them to produce acceptable, human-sounding output.
But now consider the famous Noam Chomsky sentence: “Colorless green ideas sleep furiously”. The sentence is grammatically correct, but it doesn’t mean anything. This is where the semantics come in, the meaning of words!
LLMs don’t know what any of the words it’s using mean. It’s why they tend to “hallucinate”, creating syntactically reasonable but factually incorrect prose. I like Benedict Evans’ metaphor that LLMs are like an army of infinite interns. Eager to help, but you should probably check their work.
Luckily, we’ve known a theory for over 2,000 years about how to construct and verify “real-world” meaning: logic.
LLMs and logic (or the lack thereof)
LLMs are finicky when it comes to logical reasoning. A few months ago, Berglund et al. published a paper on this which went viral, analyzing the “Reversal Curse” phenomenon where models trained on the relationship “A is B” could not infer “B is A”:

I remember reading this paper when it first came out and thinking, this is something fundamental— or rather, LLMs miss something fundamental: symbolic logical reasoning. This explains why they suck at math and why Mitchell et al. concluded that they have not developed robust abstraction abilities at a humanlike level.
This is the core issue: despite their many strengths, LLMs lack a model of the world and reasoning capabilities.
This is no surprise to OpenAI either. Here’s a snippet from an interview at Cambridge a couple weeks ago with Sam Altman:
Cambridge Student: "To get to AGI, can we just keep min-maxing language models, or is there another breakthrough that we haven't really found yet to get to AGI?"
Sam Altman: "We need another breakthrough. We can still push on large language models quite a lot, and we will do that. We can take the hill that we're on and keep climbing it, and the peak of that is still pretty far away. But, within reason, I don't think that will (get us to) AGI… Teaching it to clone human behavior and human text, I don’t think that’s going to get there. And so there's this question which has been debated in the field for a long time: what do we have to do in addition to a language model, to make a system that can go discover new physics? That will be our next quest."
So, we’ll need a new way forward for this next quest.
A way forward
I spoke with Dartmouth Professor Soroush Vosoughi about this problem a couple times last semester. He proposed combining a bottom-up approach (LLMs or, more generally machine learning/finding patterns from data) with a top-down approach (starting with structures of the world/domain knowledge and applying symbolic reasoning).
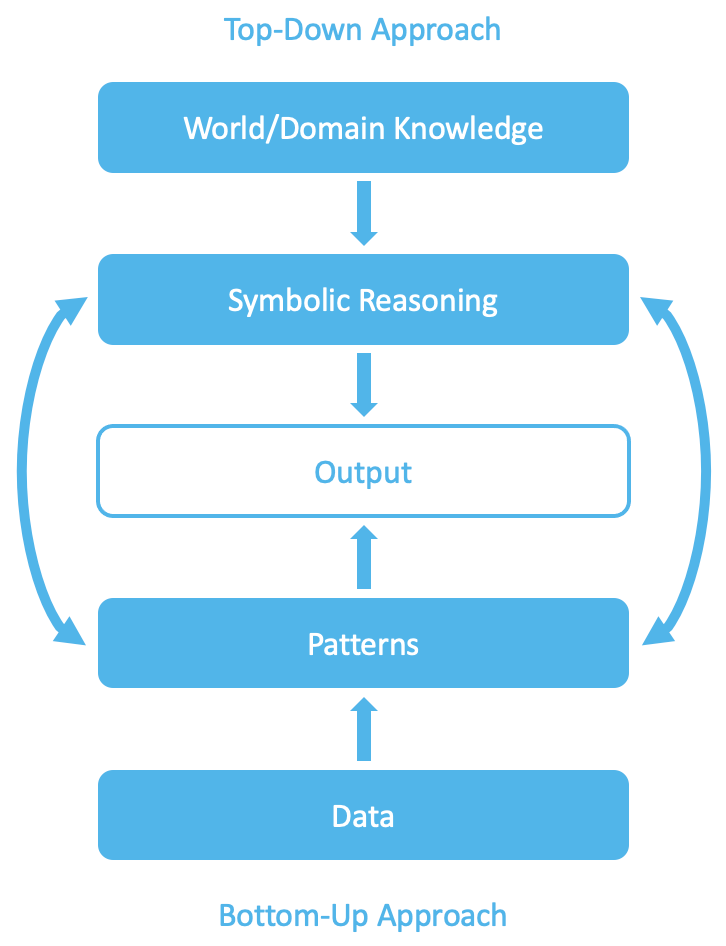
This is not unlike some models of human cognition, where we solve problems both based on our experiences (bottom-up) and using broader logical reasoning (top-down).
Top-down, “Good Old Fashioned AI” has existed for decades (see the canonical Russel and Norvig textbook). Algorithms like A* search and Dijkstra’s algorithm power GPS route planning and state-of-the-art chess bots.
In the case of language, leveraging both approaches is important. Symbolic logical discourse boils down flowery prose to its very core (re: the Foundation quote above), whereas the syntactic LLM approach helps grapple with the nuance and emotion in text. For example, no matter how you try to trick “symbolicGPT” with clever prompts to get it to mis-answer “1+1”, it will always return “2”. But symbolicGPT would likely be more sterile and banal than ChatGPT at creating a snappy slogan for your startup.
I don’t want to conflate these various concepts: though related, good old-fashioned AI, symbolic reasoning, and semantic features are all different tools to solve different problems, each with different implementation challenges. Phew. Deep breath. That was a lot. Let’s move back to the real world with a recent example.
Better together
Meta recently announced an AI system called CICERO that combines these two approaches– strategic reasoning and natural language processing– to play the board game Diplomacy at a human level. Unlike other board games like chess or Monopoly where you just need to move pieces around a board, Diplomacy involves bargaining and cooperating with other players to capture as much territory as possible. Thus, CICERO integrates a top-down planning engine to plot its next moves and then uses a dialogue engine to communicate with the other players.

I believe this is a significant development since it is a proof of concept of combining bottom-up and top-down AI to build a smarter, more capable AI agent. It would be incredible to have a CICERO-like copilot to advise a doctor deciding on a treatment plan or a hostage negotiator plan a high-stakes rescue strategy. CICERO reminds me of the JARVIS assistant from Iron Man.

Does any of this even matter though? Who cares if we have a model of reality when most of the time, LLMs just work. They help a software engineer quickly write a program using Copilot. They help little Johnny write his essay about the American Revolution. They help researchers summarize troves of academic papers in seconds. Undoubtedly, they generate tons of value for consumers.
But there are many disciplines where you’d probably want a little extra intellectual umph (i.e. a lawyer negotiating the terms of a merger agreement), and many others where a most-of-the-time-it-just-works accuracy rate is unacceptable (i.e. medical diagnoses). Here, our super-powered symbolicGPT might come in handy.
Another takeaway here is that AI is not monolithic. A one-size-fits-all model isn’t going to cut it. Much like you don’t need a freshly-minted Harvard physics PhD to find you a good vacation spot as your travel agent, so too is the most capable model not necessary for every task. Even now we’re seeing companies opt to use smaller, less-capable, and more cost-efficient LLMs for certain tasks. It’s why Google released 3 sizes of Gemini.
In the early innings of our more-capable, top-down and bottom-up AI, my best guess is that people will build them for smaller, specific use cases with well-defined problems and state spaces.
Can/how will this scale to building a model of the world or working with a graph of all human knowledge? I’m not sure. People have been pondering this problem for centuries. If you have ideas on this, drop Soroush’s lab a line. In the meantime, I’ll be reading Foundation, and learning how to play Diplomacy, of course.