

An Epiphany
As AI crested the top of the hype cycle last summer, Frank Slootman, Chairman of Snowflake, said that the technology will “become so integral to [our] daily experience” that people “will not be able to remember a world before AI”. I had one of those moments a couple months ago.
Shortly after ChatGPT’s first birthday, I was working on a project for the NFL Big Data Bowl. GPT-4 was instrumental. It helped me build the model and debug my code. When I couldn’t use GPT-4 one day, I had to go back to doing things the old-fashioned way: browsing documentation, sleuthing Stack Overflow, and parsing convoluted error messages on my own. It was so. much. slower. I could not imagine building a project of the same scale without GPT-4.
Talk of the town
I’m not alone in this realization. AI coding assistants are finally having their moment. With the launch of Cognition Labs and the massive $117 million funding round for Magic AI this month, there has been a lot of buzz. Morgan Stanley equity analysts see these assistants as one of the first major value-add use cases for LLMs.
One study of 95 developers found that those who used GitHub’s Copilot (an AI programming assistant) completed a programming task 55.8% faster than the control group without it.

Assistants like Github Copilot and Sourcegraph’s Cody integrate into an existing codebase to help developers write code, all within their IDE (the place where you write code). Check out this demo from Sourcegraph:

A promising task for Large Language Models (LLMs)
Paul Kedrosky and Eric Norlin at SK Ventures have a great framework for thinking about tasks that will be automated by LLMs.

They believe coding is ripe for LLM disruption since it is both highly grammatical (rules-based languages) and predictable (the same inputs yield the same outputs every time).
Moreover, the code output of an LLM can be compiled, executed, and tested on several cases (i.e. consider the suite of tests a program needs to pass on a LeetCode problem), presenting ample opportunities for feedback and training.
But here’s the problem: they’re not that good yet
Despite the flashy demos, these LLMs are less useful in practice. In a test of GPT-4 on 1,208 coding questions from StackOverflow, Zhong et al. found that 62% of the generated code contained API misuses. Even the Cognition Labs assistant Devan was only successful 1 in 7 times (13.86%) in resolving GitHub issues and pull requests.
Moreover, there are also concerns over code quality and maintainability. Researchers from GitClear analyzed 153 million changed lines of code and predicted that code churn -- the percentage of lines that are reverted or updated less than two weeks after being authored -- will double in 2024 vs 2021, a pre-AI baseline.
I’ve had mixed experiences building with these tools myself. I am still excited about the impact of AI on programming (more on this in part 2) but think the technology has a ways to go. Its utility is not monolithic. I’ve found it works better in some situations than others, and in this blog post, I’ll share a framework I developed to think about the current level of AI coding assistant’s utility.
A framework for AI coding utility
There are two components to understanding the utility of any tool:
1. Capability - How good the tool is at accomplishing a task
2. Usefulness - How much value does the tool provide to a specific user for that task (i.e. costs vs benefits)
Let’s reframe this in terms of LLMs:
1. Capability - How good the LLM is at coding?
2. Usefulness - How much does it help an individual programmer?
I believe there are three key variables at play:
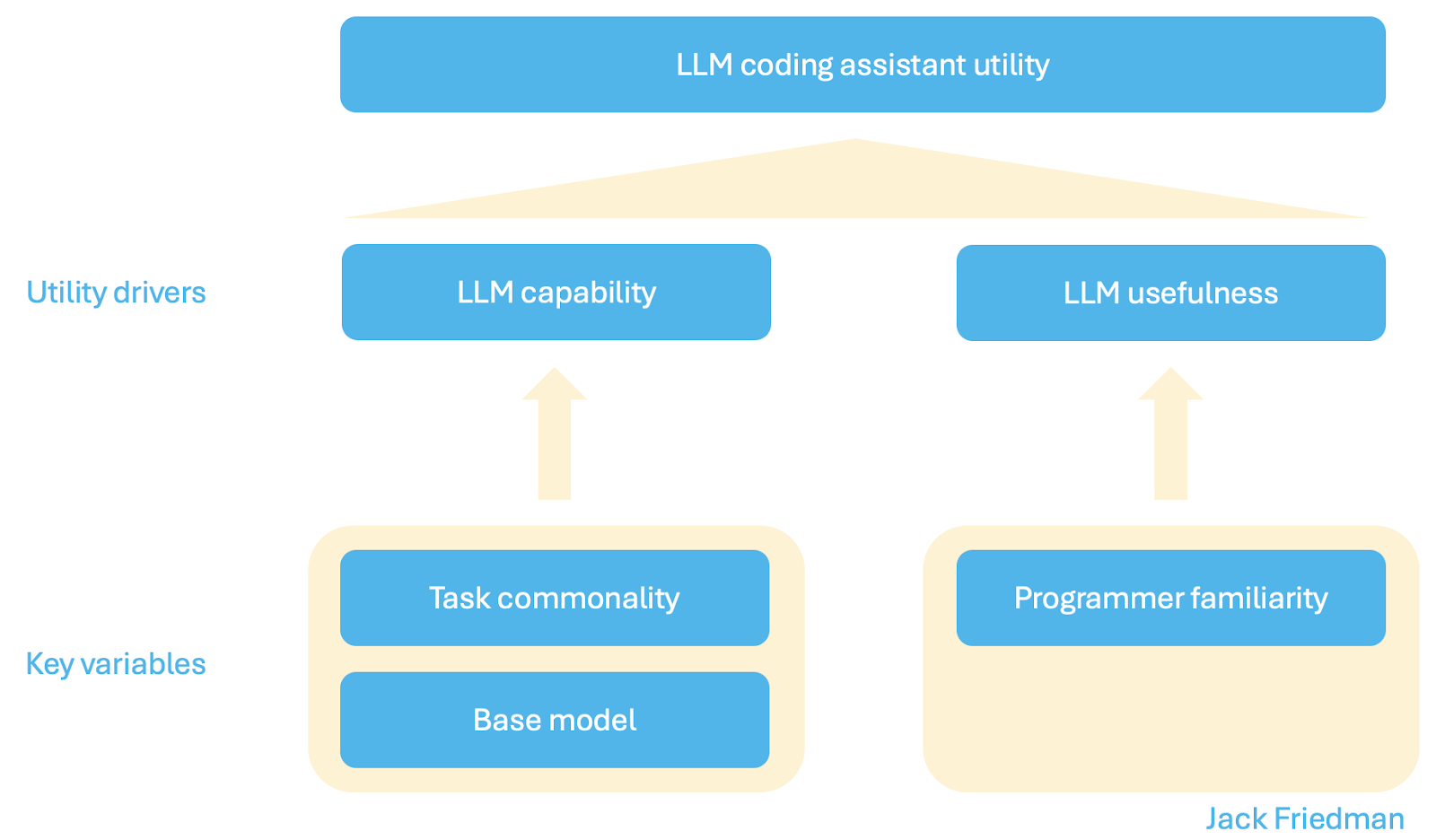
Let’s tackle each of these three variables.
Variable 1: Task commonality
This variable measures how often your task (or something similar to it) is seen in the LLM’s training data.
As I wrote in Beyond Large Language Models, LLMs are not reasoning about the code they write. They repeat statistical regularities from their training data and struggle to generalize to problems they haven’t seen before. Therefore, when an LLM sees several examples of a task in its training data, it will perform better on it. The converse is also true—LLMs perform worse on unseen tasks.
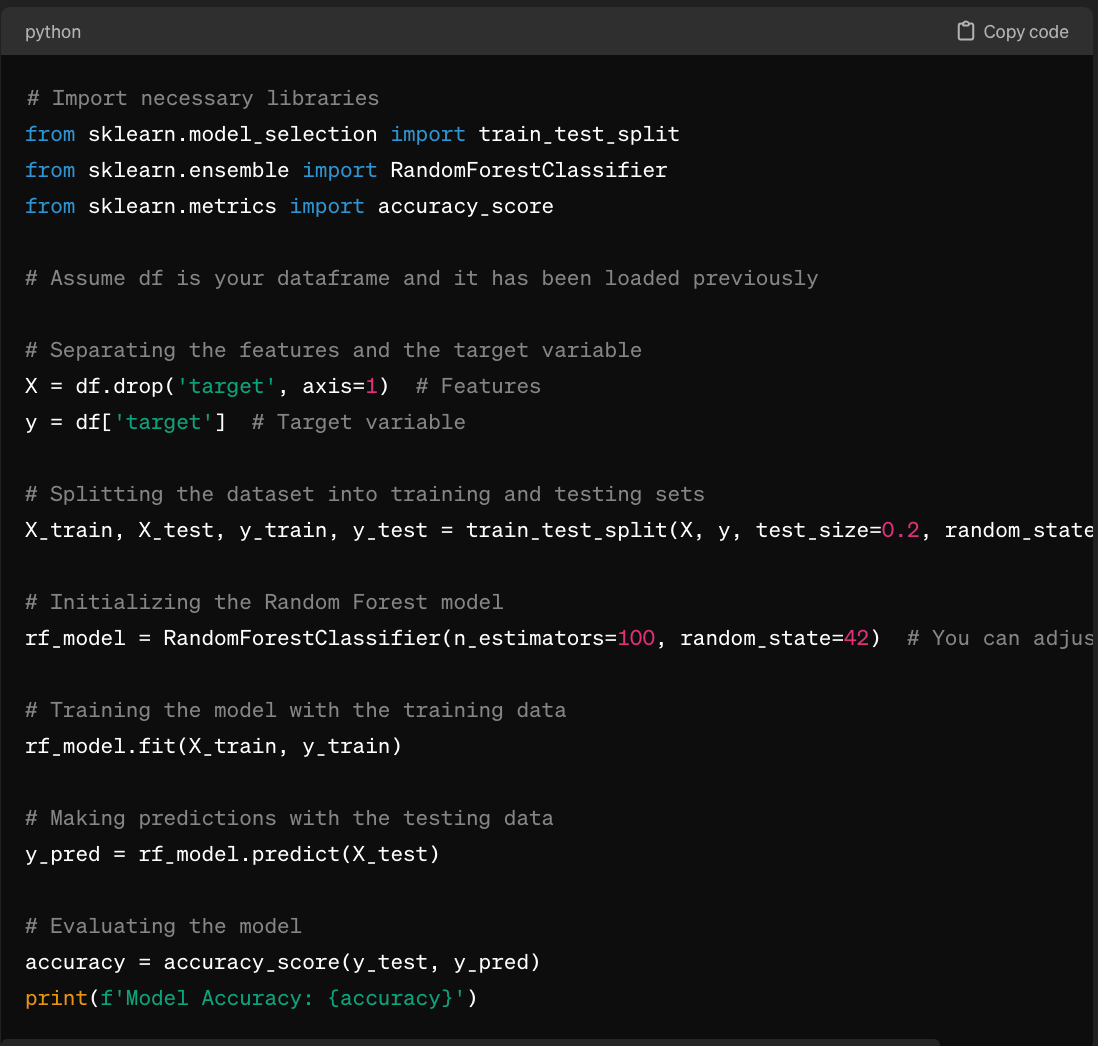
This explains why LLMs are great at writing boilerplate code- they’ve seen it time and time again, and the code is always the same. For example, an LLM is good at building a random forest model using scikit-learn since the code is the same for every scikit-learn model, and there are a ton of examples of scikit-learn on the internet.
However, when I was building a RAG model to predict financial risk a few weeks ago, ChatGPT bombed. It made up functions that didn’t exist and screwed up the syntax. This makes sense since LangChain is relatively new, meaning there is less documentation and fewer code examples in its training data.
Experiments confirm. LLMs struggle to generalize on complex, uncommon tasks. OpenAI reported that GPT-4 only got an ELO rating of 392 on competitive programming contests from Codeforces, which is very low. Horace He found that of the easiest problems on Codeforces, it solved 10/10 problems pre-2021 and 0/10 recent problems, after the training data cutoff. This suggests there may be data leakage– GPT-4 may have seen these problems during training and memorized the solutions.
A corollary here is that LLMs will also tend to underperform on more difficult problems since there are fewer examples in the training data.
Since many programs are isomorphic to something that’s already been written before, these LLMs are pretty helpful programming assistants. But they are limited in terms of scope.
To summarize, an LLM is better at writing code for tasks they have seen often in their training data than those that are niche, complicated, and require advanced reasoning to solve.
Variable 2: Base LLM
Some LLMs are better than others. I won’t opine on model architecture here, but there are various benchmarks to evaluate various LLMs.

Variable 3: Programmer familiarity
I’ve found LLMs to be very helpful when I’m less familiar with a library, programming language, or API. For example, when I was working on the NFL Big Data Bowl project, GPT-4 was instrumental in learning the best practices for using Pytorch Lightning to build some of the models.
However, LLMs are less helpful for more familiar tasks. When using an AI coding assistant, the development process still includes a human-in-the-loop to review the code:

Great software engineers who are intimately familiar with a library or framework don’t need an LLM to solve a task for them. It will be quicker for them to write the program themselves instead of reviewing and debugging code written by an LLM.
Putting it all together
Assuming you’re using a state-of-the-art LLM, we can aggregate these findings into a utility matrix:

In addition to writing the code itself, LLMs also help with other vectors of the software development lifecycle. They can speed up debugging, explain a part of a code base or convoluted API documentation, create test cases, draft documentation, and act as an infinitely patient pair programmer.
What’s next
I have no doubt the capabilities of LLMs will improve. Even between the time I started thinking about this blog post and now, much has changed. Many researchers and companies are working on this problem, and bigger, more capable foundation models like GPT-5 and Llama 3 are on the horizon this year. There are three ways I see LLMs improving at coding from a technical standpoint.
First is more training data. After seeing more examples, the frontier of unseen/niche problems shrinks. Thus, they will become better “stochastic parrots” able to solve more problems. This explains why the LangChain error I encountered will be patched soon. [1]
The second way LLMs will improve is with better training. Techniques like reinforcement learning, imitation learning, and self-play improve the quality of LLM output.
The final way LLMs will improve with new model architectures– more parameters, more efficient model structure (i.e. mixture of experts vs single decoder-only), larger context windows, improved long-term memory, and more. [2]
All three of these techniques will improve an LLM’s capabilities. As the number of problems LLMs can solve increases, programmers will have to spend less time checking their code, increasing their utility.
Conclusion
Overall, AI coding assistants show massive promise. They provide a lot of utility to programmers on common, unfamiliar tasks. But they will need an upgrade to speed up the software development process on more difficult ones. In the next part of this series on AI and programming, I’ll share some applications of this technology that I’m excited about. As always, I’d love to hear your thoughts. Feel free to reach out!
Footnotes
[1] I’m curious how much more unseen coding data is available. Engineers have already scoured the largest repositories of code like GitHub. Though imitation learning and reinforcement learning can help get around some of these issues, It’s not immediately clear to me how much more publicly available data is left.
[2] Another technique I’m excited about is creating an orchestra of models that all work together. A conductor model might interact with one model to do high-level planning, another to do coding, and maybe even another to do debugging.